cluster
기본적으로 싱글 프로세스로 동작하는 node.js가 cpu 코어를 모두 사용할 수 있게 해주는 모듈입니다.
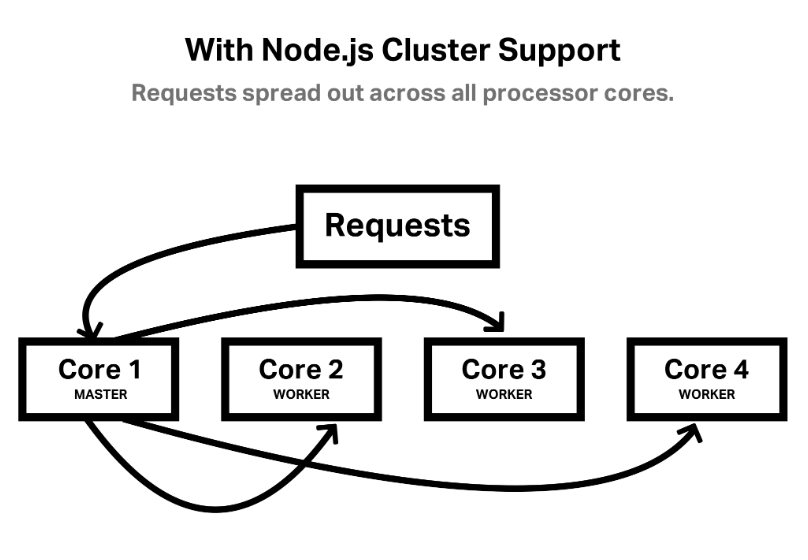
포트를 공유하는 node.js 프로세스를 여러 개 둘 수도 있어서 요청이 많이 들어왔을 때 병렬로 실행된 서버의 개수만큼 요청이 분산되게 할 수 있습니다.
메모리를 공유하지 못하는 등의 단점도 있어서 세션을 메모리에 자장하는 경우 문제가 될 수도 있지만 이는 Redis 등의 DB를 도입해 해결할 수 있습니다.
cluster에는 마스터 프로세스와 워커 프로세스가 있는데 마스터 프로세스는 cpu 개수만큼 워커 프로세스를 만드는데 워커 프로세스가 실질적인 일을 하는 프로세스입니다.
js
const cluster = require("cluster");
const http = require("http");
const numCpus = require("os").cpus().length;
if (cluster.isMaster) {
for (let i = 0; i < numCpus; i++) {
cluster.fork();
}
// 워커 종료 시...
cluster.on("exit", (worker, code, signal) => {
// code: process.exit의 인수로 넣어준 코드값이 전달됩니다.
// signal: 존재하는 경우 프로세스를 종료한 신호의 이름이 전달됩니다.
console.log(`${worker.process.pid}번 워커가 종료되었습니다.`);
});
} else {
http
.createServer((req, res) => {
res.writeHead(200, {
"Content-Type": "text/html; charset=utf-8",
});
res.write("<p>helloworld</p>");
res.end("bye");
setTimeout(() => {
process.exit(1);
}, 1000);
})
.listen(8086);
console.log(`${process.pid}번 워커 실행`);
}
예기치 못한 에러로 인한 서버가 종료되는 현상을 방지할 수 있어서 클러스터링을 적용해두는 것이 좋습니다.
직접 cluster 모듈로 클러스터링을 구현할 수도 있지만 실무에서는 pm2 등의 모듈을 사용하면 됩니다.